-
Whisper 사용해보기: Open AI의 음성 받아쓰기AI 2023. 2. 12. 01:53반응형
https://openai.com/blog/whisper/
Introducing Whisper
We’ve trained and are open-sourcing a neural net called Whisper that approaches human level robustness and accuracy on English speech recognition. Read Paper View Code View Model Card Whisper examples: Reveal Transcript Whisper is an automatic speech rec
openai.com
Whisper는 초거대 AI 언어모델인 GPT-3로 잘 알려져 있는 OpenAI사에서 MIT 라이센스로 배포한, 실시간 음성인식/번역 엔진입니다.

환경 구축하기
홈페이지에 자세하게 나와 있고 최신 내용이 반영되니 참고만 하고 홈페이지를 확인하는게 제일 좋습니다.
1. Python 3.7 이상
https://www.python.org/downloads/에서 적당한 버전을 다운로드 받아 설치합니다. 저는 3.8.10을 사용 하고 있습니다.
2. Pytorch
https://pytorch.org/get-started/locally/을 참고하여 본인 PC의 여건에 맞는 버전으로 설치합니다.
nVIDIA GPU가 없는 분이라면 명령프롬프트에서 다음과 같은 명령어로 설치하면 됩니다.
pip3 install torch torchvision torchaudionVIDIA GPU가 있다면 파이토치의 CUDA 활성화 방법과 관련된 블로그를 참고하여,
CUDA 11.6 또는 11.7버전, 그리고 이에 맞는 CUDNN 파일을 다운로드 받아 CUDA를 활성화 시킵니다.
3. FFMPEG
윈도우는 choco 로 맥은 brew 로 ffmpeg를 설치해 줍니다. :)
4. Whisper 모듈
pip install git+https://github.com/openai/whisper.git위 명령어를 이용해 Whisper 모듈을 설치 해 줍니다.
자세한 건 앞에서도 언급했지만 홈페이지를 참고해서 설치하는게 가장 좋습니다.
설치완료 후에는 Whisper는 Python 스크립트를 통해서 구동할 수도 있지만, 실행파일 형태로도 제공되기 때문에 명령프롬프트에서 사용할수 있습니다.
usage: whisper [-h] [--model {tiny.en,tiny,base.en,base,small.en,small,medium.en,medium,large}] [--model_dir MODEL_DIR] [--device DEVICE] [--output_dir OUTPUT_DIR] [--verbose VERBOSE] [--task {transcribe,translate}] [--language {af,am,ar,as,az,ba,be,bg,bn,bo,br,bs,ca,cs,cy,da,de,el,en,es,et,eu,fa,fi,fo,fr,gl,gu,ha,haw,hi,hr,ht,hu,hy,id,is,it,iw,ja,jw,ka,kk,km,kn,ko,la,lb,ln,lo,lt,lv,mg,mi,mk,ml,mn,mr,ms,mt,my,ne,nl,nn,no,oc,pa,pl,ps,pt,ro,ru,sa,sd,si,sk,sl,sn,so,sq,sr,su,sv,sw,ta,te,tg,th,tk,tl,tr,tt,uk,ur,uz,vi,yi,yo,zh,Afrikaans,Albanian,Amharic,Arabic,Armenian,Assamese,Azerbaijani,Bashkir,Basque,Belarusian,Bengali,Bosnian,Breton,Bulgarian,Burmese,Castilian,Catalan,Chinese,Croatian,Czech,Danish,Dutch,English,Estonian,Faroese,Finnish,Flemish,French,Galician,Georgian,German,Greek,Gujarati,Haitian,Haitian Creole,Hausa,Hawaiian,Hebrew,Hindi,Hungarian,Icelandic,Indonesian,Italian,Japanese,Javanese,Kannada,Kazakh,Khmer,Korean,Lao,Latin,Latvian,Letzeburgesch,Lingala,Lithuanian,Luxembourgish,Macedonian,Malagasy,Malay,Malayalam,Maltese,Maori,Marathi,Moldavian,Moldovan,Mongolian,Myanmar,Nepali,Norwegian,Nynorsk,Occitan,Panjabi,Pashto,Persian,Polish,Portuguese,Punjabi,Pushto,Romanian,Russian,Sanskrit,Serbian,Shona,Sindhi,Sinhala,Sinhalese,Slovak,Slovenian,Somali,Spanish,Sundanese,Swahili,Swedish,Tagalog,Tajik,Tamil,Tatar,Telugu,Thai,Tibetan,Turkish,Turkmen,Ukrainian,Urdu,Uzbek,Valencian,Vietnamese,Welsh,Yiddish,Yoruba}] [--temperature TEMPERATURE] [--best_of BEST_OF] [--beam_size BEAM_SIZE] [--patience PATIENCE] [--length_penalty LENGTH_PENALTY] [--suppress_tokens SUPPRESS_TOKENS] [--initial_prompt INITIAL_PROMPT] [--condition_on_previous_text CONDITION_ON_PREVIOUS_TEXT] [--fp16 FP16] [--temperature_increment_on_fallback TEMPERATURE_INCREMENT_ON_FALLBACK] [--compression_ratio_threshold COMPRESSION_RATIO_THRESHOLD] [--logprob_threshold LOGPROB_THRESHOLD] [--no_speech_threshold NO_SPEECH_THRESHOLD] [--threads THREADS] audio [audio ...]SizeParametersEnglish-only modelMultilingual modelRequired VRAMRelative speed
tiny 39 M tiny.en tiny ~1 GB ~32x base 74 M base.en base ~1 GB ~16x small 244 M small.en small ~2 GB ~6x medium 769 M medium.en medium ~5 GB ~2x large 1550 M N/A large ~10 GB 1x 모델은 위와 같이 tiny부터 large까지. 그리고 영문 전용 모델과, 다중언어 모델이 있습니다.
인식 가능한 언어가 굉장히 많고, 한국어도 지원합니다.
영어는 base, small로도 어느 정도 인식이 되지만 한국어는 small까지에서 품질이 나빠 medium은 되어야 괜찮은 품질이 나옵니다.
다만, GPU 메모리 용량 제한이 있다 보니, 제 랩탑에 들어 있는 1050Ti 4GB로는 small 모델까지만 CUDA 가속이 가능했습니다.
CPU로 구동할 경우 CUDA 가속이 뒷받침 되는 환경에 비해 매우매우!! 느립니다.
상세 사용방법은 다음 링크를 참고해주세요.
https://github.com/openai/whisper#readmetranscribe 기능과 translate 기능이 있는데
transcribe는 영상의 언어를 그대로 텍스트로 출력해 주는 기능이며,
translate 기능은 영상의 언어를 '영어'로 번역해주는 기능입니다.
한국어를 지원한다는 것은, 영상의 언어가 한국어일때 알아듣는다는 이야기이며, 번역을 한국어로 해 내지는 못합니다.
사용해보기
사용 방법은 기본적으로 다음과 같습니다.
whisper sample.mp3사용할 모델을 특정하는 방법입니다.
처음 사용하는 모델은 다운로드 후 실행 됩니다.
whisper --model small sample.mp3언어를 특정해 주는 기능입니다.
지정하지 않으면 초반 30초에서 언어를 자동으로 디텍팅합니다.
whisper --language ko sample.mp3가속장치를 특정해 주는 기능입니다.
cuda가 사용 가능한 경우 cuda를 먼저 사용하려 하기 때문에 메모리 부족 상황에서 실행이 되지 않을 수 있습니다.
따라서 강제로 cpu를 사용하고자 하는 경우 --device cpu 옵션을 꼭 사용해줘야 했습니다.
whisper --device cuda sample.mp3 whisper --device cpu sample.mp3태스크를 받아쓰기 / 영어번역 중에 고르는 기능입니다.
whisper --task transcribe sample.mp3 whisper --task translate sample.mp3이제 응용을 해서 실제로 사용해 보겠습니다.
샘플은 유튜브 링크를 MP3 파일로 바꿔주는 사이트를 이용해서 뽑아냈습니다.
첫번째 샘플입니다.
테슬라 AI Day 관련 Cnet에서 하이라이트를 뽑아놓은 영상 샘플입니다.
www.youtube.com/watch?v=Gm6dZ1q06ks
small.en 모델을 사용했습니다.

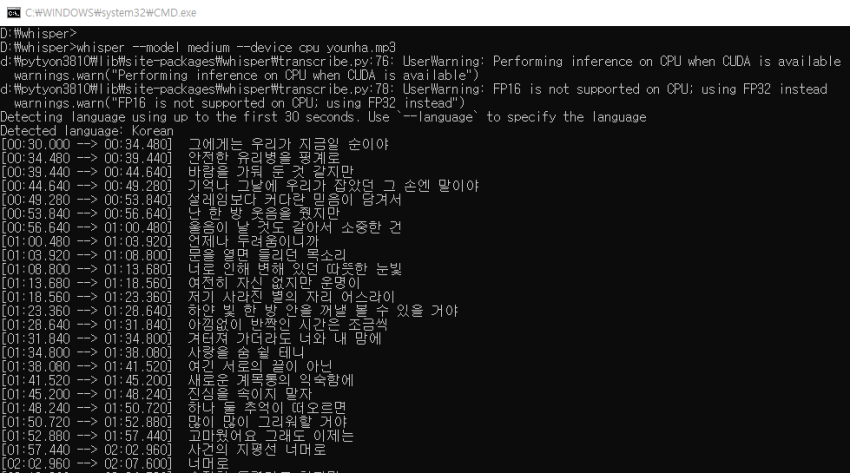
두번째 샘플입니다.
윤하의 '사건의 지평선' 노래입니다.
한국어는 영어보다는 인식률이 다소 떨어지는 모습입니다.
앞부분을 잘라먹는 모습도 보입니다.
세번째 샘플입니다.
MBC 뉴스입니다.http://www.youtube.com/watch?v=bVZl9keFdMo
small 모델과 medium 모델을 연달아 보시겠습니다.


Medium이 훨씬 나은 모습인데, 인식률이 좋지 않은 부분은 실제 영상과 비교해서 들어보면 어느 정도 납득이 되는 수준입니다.
제가 직접 들으며 받아 써 봤는데,
에..., 저.., 그..., 이.. 같은 부분은 알아서 걸러주는 모습을 보입니다.
'남탓'을 '난탓'이라고 잘못 적은 줄 알았던 부분은, 실제로 발언자가 그렇게 발음을 했습니다.
[기자] 대통령님, 그 순방 전부터 특정 언론사에 대해서 그, 전용기, 대통령 전용기 탑승을 배제하면서 쫌 논란이 되고 있는데, 대통령님 입장이 있으신지 궁금합니다. [대통령] 대통령이 국민이, 그 이 많은 그 국민들의 그 세금을 써가며 에 이런 해외 순방을 하는 것은 것이 중요한 국익이 걸려있기 때문입니다. 그리고 에 우리 기자 여러분께도 외교 안보 이슈에 관해서 에 취재 편의를 제공해 온 것이고 그런 차원에서 받아 들여주시면 되겠습니다. [사라지는 대통령을 보며 기자가] 이상민 장관 경질론에 대해서는 의견 없으신가요? [박홍근 원내대표 / 더불어민주당] 오만과 독선, 불통해의 국정 운영만 고집합니다. 야당 탓, 전 정부 탓, 언론 탓, 제도 탓 등 실적의 모든 원인을 난 탓으로 돌리기에 바쁩니다. 국제 외교 무대에서 자신이 비속어를 내뱉어 평지풍파를 일으켰으면서도 반성은 커녕 순방 전용기에 보도 언론사의 탑승을 치졸하게 불허하는 뒤끝작렬 소인배 같은 보복 행위마저 이어갑니다.어디에 활용하면 좋을까..
아직 인식이 완벽하지 않고, 버그도 있습니다.. (인식하기 어려운 음성의 경우 메아리처럼 같은 문장이 반복해서 찍히는 현상 등)
그래도, 재미 삼아? 또는 누군가에게는 업무나 취미용으로 유용하게 사용될 것 같습니다.
MIT 라이센스라 회사에서 사용하더라도 문제가 없기도 하구요.
회의록 작성?
한국어로 회의를 한 내용을 정리할 목적이라면, 네이버의 클로바노트가 더 편리할 것입니다. 일단 처리 속도가 월등히 빠릅니다.
그런데, 회사에서 회의 한 내용이 보안사항이라면 네이버에 업로드 하는 것이 찝찝할 수 있을 것입니다.
Whisper는 내 PC 안에서 처리하는 것이다보니 보안 측면에서 좀 더 안전한 대안이 될 것 같습니다.
물론 사람이 초안을 보고 수정은 해줘야지요.
외국어로 된 강의 듣기
영어는 상당히 받아쓰기를 잘 합니다.
그리고 영상은 Full Time을 소비해서 들어야 하지만, 텍스트는 이보다 훨씬 빨리 읽을 수 있습니다.
관심 있는 외국어 영상이 있다면 일단 텍스트로 뽑아낸 다음 파파고/구글번역을 한 단계 거치면 꽤 수준 높은 번역본이 나와 유용하게 쓸 수 있습니다.
영상 자막 제작
whisper를 실행 시키면 자동으로 폴더 내에 .srt , .txt, .vtt 파일이 생성됩니다.
자막을 만들 때 가장 힘든 부분이 싱크를 맞추는 부분인데, 완성도가 약간 떨어지더라도 타임프레임이 찍힌 초안을 빠르게 만들어준다면 자막 제작에 도움이 많이 될 것으로 보입니다.
 반응형
반응형'AI' 카테고리의 다른 글
[VGG16 전이학습] 강아지 고양이 분류 (0) 2023.01.16